计算机体系架构简述
简介
- 计算机系统 = 硬件 + 软件
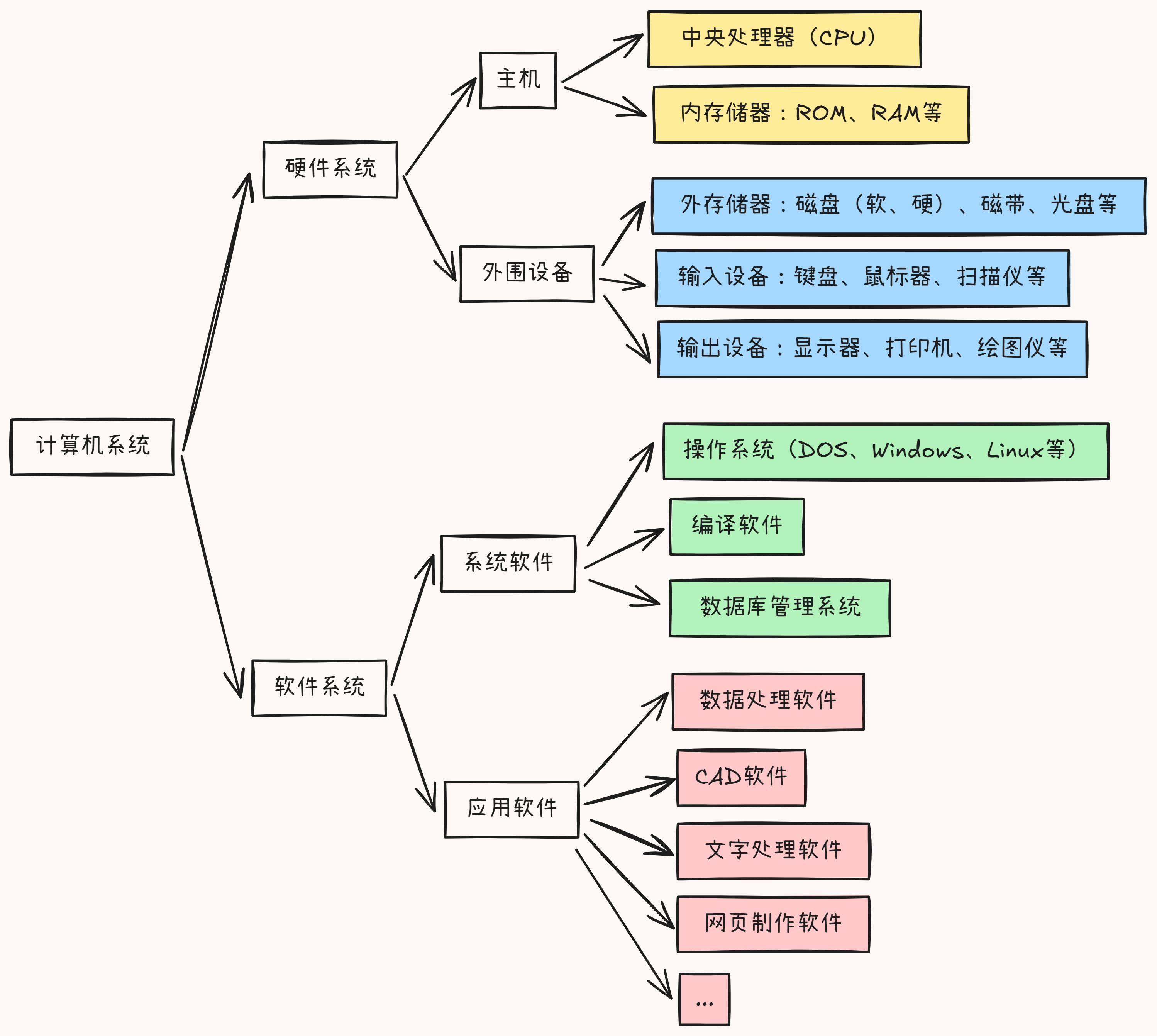
计算机硬件系统组成
-
运算器(ALU, Arithmetic Logic Unit): 实现算术运算和逻辑运算的部件
- 组成
- 算术单元: 处理加减乘除计算(全加器,乘法器等)
- 逻辑单元: 处理逻辑运算(门电路等)
- 移位器: 处理数据的移位
- 寄存器组
- 通用寄存器: 存储数据、运算过程的中间/临时变量等
- 状态寄存器: 记录运算过程的状态(溢出、负值、零值等),可用于指令跳转的条件判断
- 多路选择器等
- 组成
-
控制器: 向计算机各部件发出控制信息的部件
- 组成
- 指令部件
- 程序计数器PC: 提供要执行的指令地址
- 指令寄存器IR: 寄存现行指令
- 指令译码器ID: 解释现行指令,产生相应的控制信号
- 时序部件: 产生计算机运行所需的时序信号
- 微操作信号发生器: 产生执行指令的微操作控制信号
- 指令部件
- 组成
-
存储器: 存储程序的指令和数据信息
- 层次结构(从上到下: 速度由快变慢,容量由低变高,价格由高变低)
- 寄存器
- Cache(高速缓冲存储器)
- 主存(内存)
- 辅存/外存(硬盘等)
- 层次结构(从上到下: 速度由快变慢,容量由低变高,价格由高变低)
-
总线: 连接各个部件,传输数据
- 地址总线: 传输 CPU 需要操作的内存地址
- 数据总线: 传输内存数据
- 控制总线: 发送、接收信号并响应(中断、设备复位…)
-
适配器: 连接输入/输出设备与I/O总线、传输数据
-
输入设备: 将各种形式的输入信息转换为机器可接受的编码形式。例如键盘、鼠标等
-
输出设备: 将计算机处理结果转换成人们或其他设备所能接收的形式。例如显示器、打印机等
计算机体系结构
冯·诺依曼结构
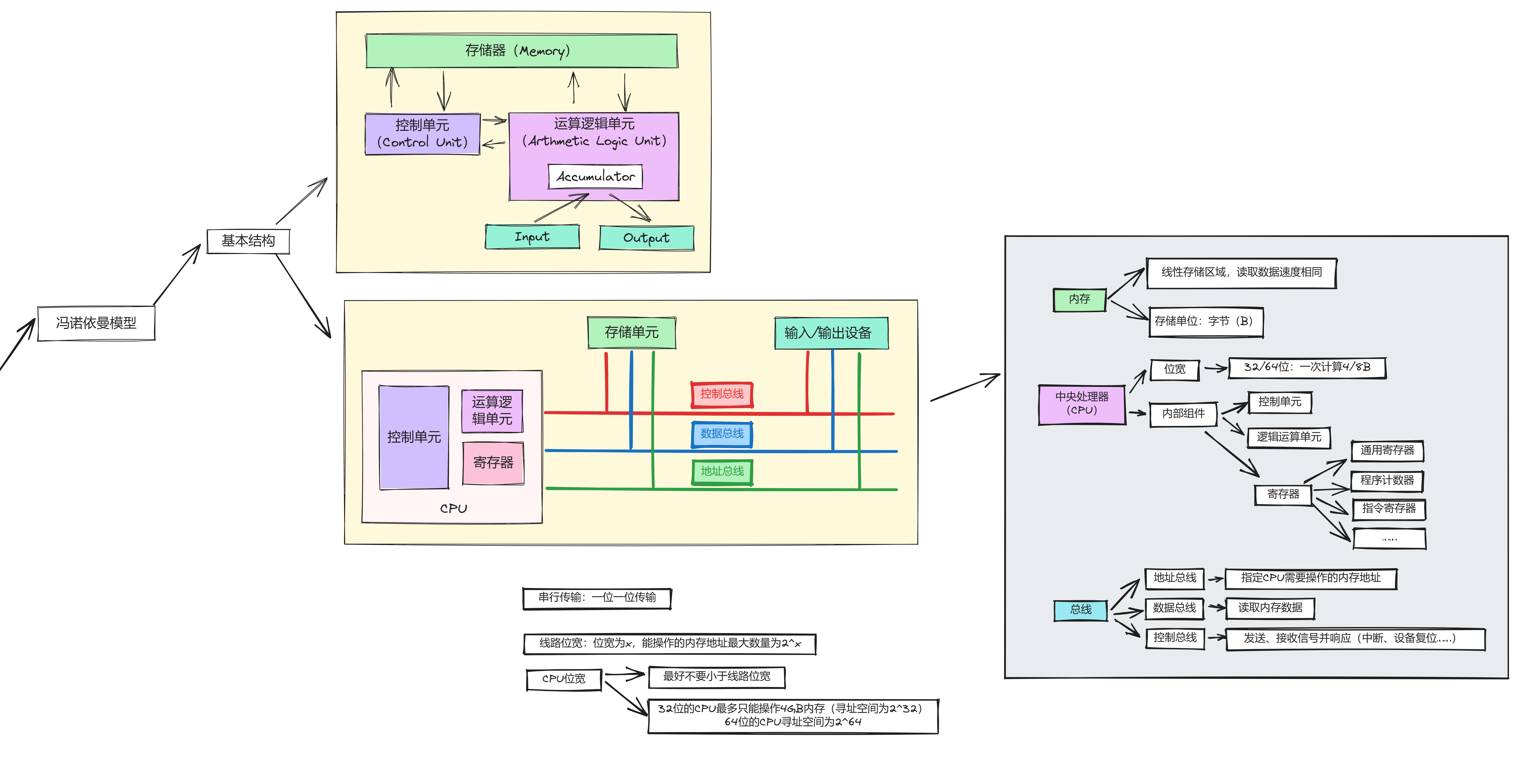
- 特点
- 程序存储,按地址访问
- 使用二进制表示数据
- 以运算器为中心
- 指令顺序执行
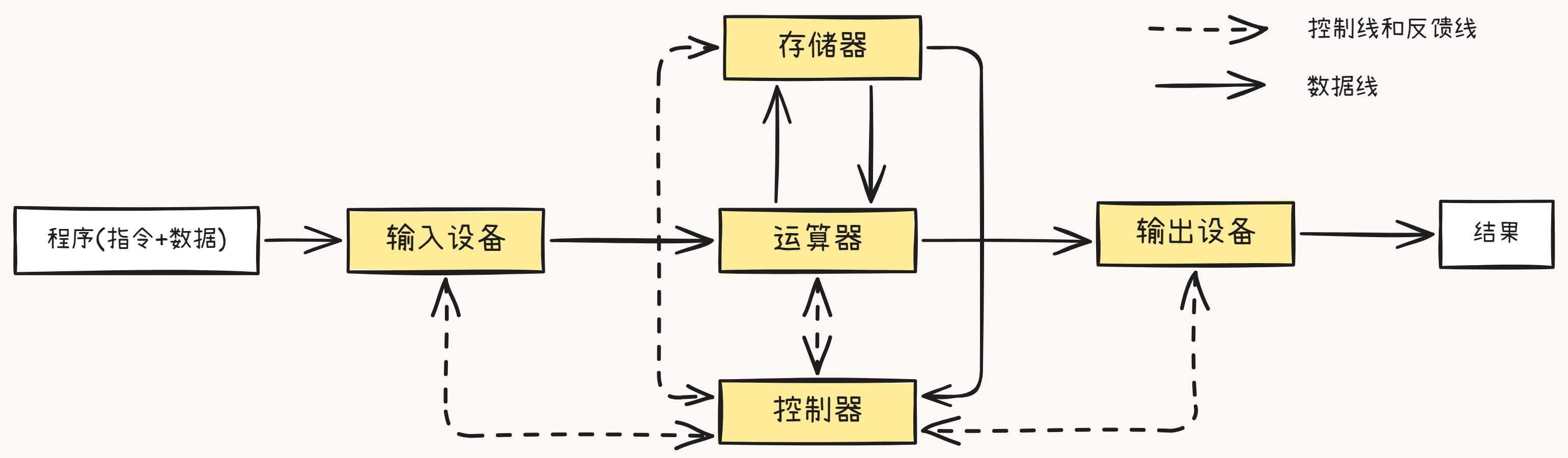
- 改进后的冯·诺依曼计算机使其从原来的 以运算器为中心 演变为 以存储器为中心 。从系统结构上讲,主要是通过各种并行处理手段提高计算机系统性能
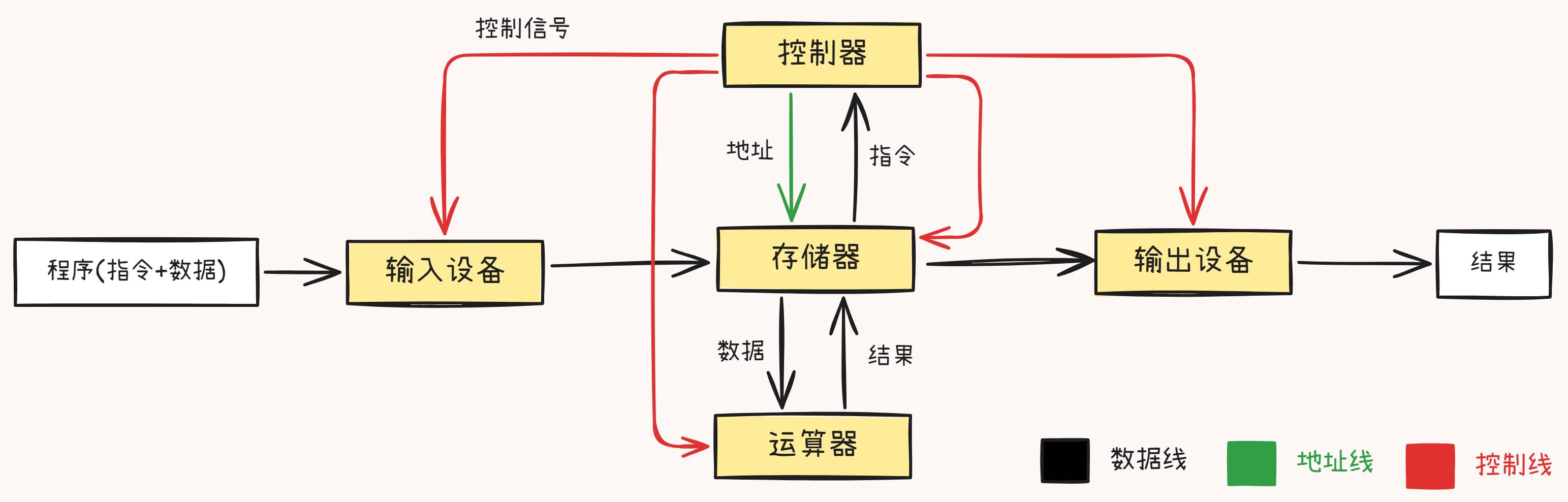
哈佛结构
- 区别与冯·诺依曼结构的特点
- 指令和数据存储器、总线区分开(指令和数据可能有不同的数据宽度)
- 改进的哈佛结构
- 程序和数据地址空间隔离,但可以从程序地址空间读取数据(大部分MCU使用这种方式)
- 程序和数据地址共享,将程序和数据的缓存分开
现今的处理器,从总线上看是冯·诺依曼结构,但 Cache 结构的设计使得其内部类似改进的哈佛结构(L1 Cache 分为 数据缓存 和 指令缓存, L2/L3 Cache 共享)
性能指标
-
吞吐量: 表征一台计算机在某一时间间隔/单位时间内能够处理的信息量
-
响应时间: 表征从输入有效到系统产生响应并得到结果之间的时间度量,用时间单位来度量
-
利用率: 在给定的时间间隔内,系统被实际使用的时间所占的比率,用百分比表示
-
处理器字长: 处理机运算器中一次能够完成二进制数运算的位数(通常是8的倍数,字长标志着机器表示数的精度。字长越长,精度越高)
-
总线宽度: 一般指 CPU 中运算器与存储器之间进行互连的内部总线二进制位数(总线宽度一般为处理机字长的1、2、4倍)
-
CPU 主频(时钟频率) = 1 / CPU 时钟周期
- 主频度量单位是 MHZ(兆赫兹)、GHZ(吉赫兹)
- 时钟周期度量单位 (微秒), (纳秒)
-
CPU 执行时间: 表示 CPU 执行一段程序所占用的 CPU 时间
- CPU 执行时间 = CPU 时钟周期数 * CPU 时钟周期长 = 指令条数 / (MIPS * )
- CPU 执行时间 = CPU 时钟周期数 / 主频 = (指令条数 * CPI) / 主频
-
CPI: 表示每条指令的周期数。即执行一条指令所需的平均时钟周期数
- 执行一条指令的耗时 = CPI * CPU 时钟周期
-
IPS: 每秒执行指令数
- IPS = 1 / (平均 CPI * CPU 时钟周期) = 主频 / 平均 CPI
-
MIPS: 每秒百万条指令数,即单位时间内执行的指令数
- MIPS = 指令条数 / (CPU 执行时间 * ) = 主频 / (CPI * )
-
FLOPS: 每秒浮点操作次数(K/M/G/TFLOPS)
-
MFLOPS: 每秒百万次浮点操作次数
目录
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Forgotten Area!