高速缓冲存储器(Cache)
简介
- 存储器层次结构的本质是,每一层存储设备都是较低一层的缓存
- Cache
- 位于 CPU 和主存之间的高速小容量存储器(一般由 SRAM 构成)
- 功能: 弥补 CPU 和主存之间的速度差异
- 理论基础: 程序的空间局部性原理
- 相关数据单位
- 块(约定多个字组成): 存储在缓存中的数据集合,数据块在缓存与主存/下一层缓存之间来回传输
- 行: 一般称 Cache 的一个数据块(容器)为行,在组成上,两者有所差别,行包含块和其它信息(一般是作为该容器的相关标识,例如有效位和标记位)
组织结构
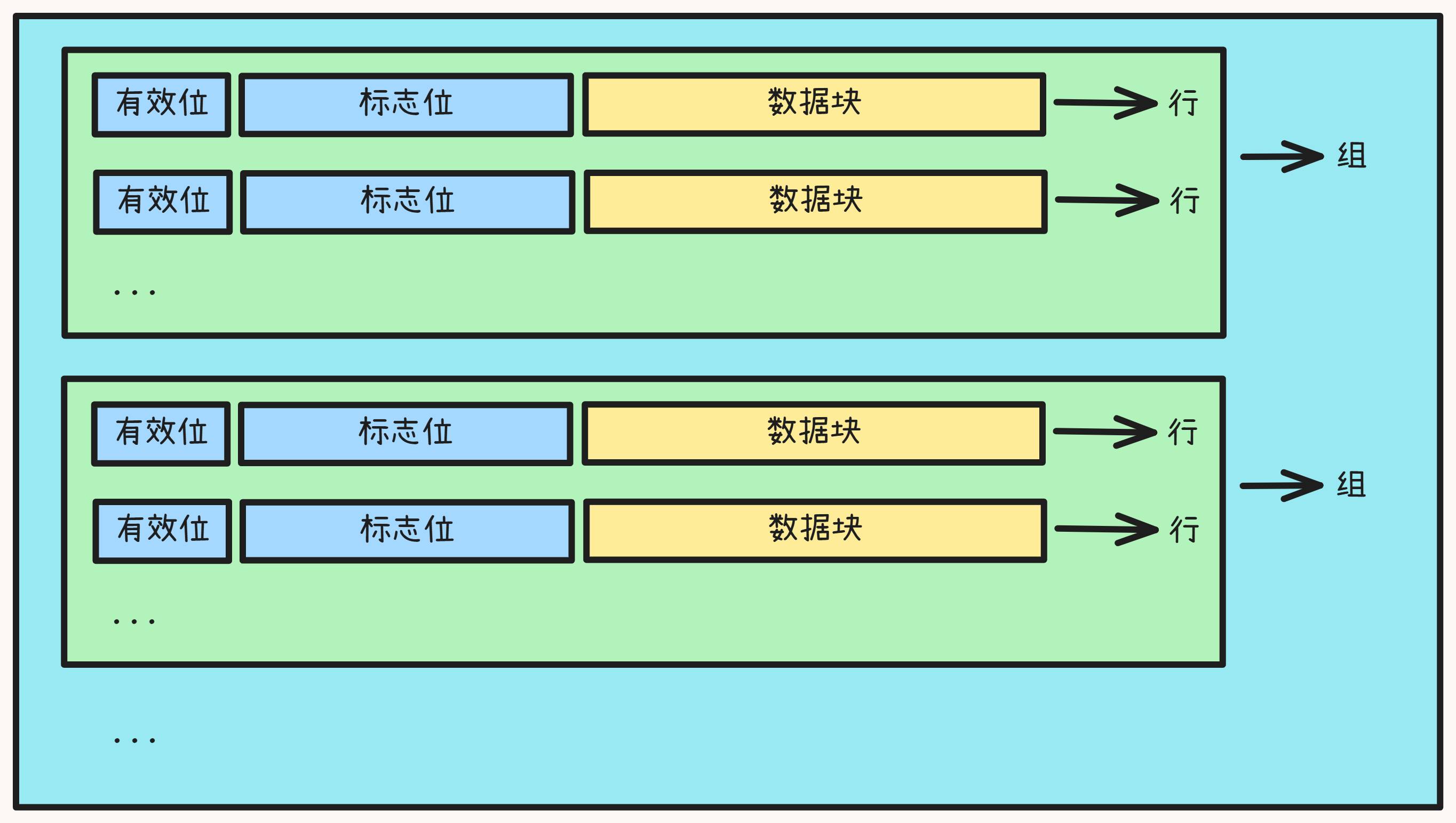
基本结构
- 存储器: 地址 位, 大小为
- Cache
- 共 组
- 每组有 行
- 每行包括一个有效位
- 字节的数据块
- 个标记/标志位(标志位是内存地址的其中 t 位,由于可能有多个内存地址映射到Cache同行中,因此需要标志位作为唯一标识)
- 大小 (不计标记位和有效位)
- 内存地址划分
- 标志位: t位
- 组号: s位(不位于高位,使得临近数据块保存在不同组中,更好利用空间局部性原理)
- 位偏移: b位

缓存请求流程
预设
系统组成: CPU <-> 缓存(Cache) <-> 主存
简要流程
- CPU 执行读取数据的指令
- CPU 向 Cache 请求数据
- 若 Cache 内部有该数据(缓存命中),直接传输给 CPU,执行 4
- 否则(缓存不命中),执行 3
- CPU 向主存请求数据,数据到达后,Cache 存储对应的数据块
- CPU 执行下一步操作
缓存读
发生时期:CPU 想要读取字/数据
缓存命中
- 现象: Cache 内部有 CPU 需要的字/数据
- 处理策略: Cache 直接向 CPU 传输数据
缓存不命中
- 类型
- 强制性不命中: Cache 内部为空
- 冲突不命中: 请求的数据与缓存的数据不一致,位置冲突
- 容量不命中: 缓存太小了,访问的数据大小超过的缓存的大小
- 处理策略
- 主存数据块先复制到 Cache 中,再传输到 CPU
- 主存数据(字)传输到 CPU,同时该字所属数据块传到 Cache 中
缓存写
发生时期:CPU 想要写入字/数据
写命中
- 现象: 想要写入数据的地址在缓存中
- 处理策略
- 透写(Write Through): 同时更新缓存和主存(CPU 写主存无高速缓存作用,适用写数据较少的情况)
- 回写/延迟写入(Write Back/Write Deferred): 数据先只在缓存中更新,之后更新到主存中(减少 CPU 对主存的访问,存在数据不一致性隐患)
- 更新到主存的时机: 修改内容所在的缓存即将被另一个缓存替换
- 脏位(Dirty Bit)标记,当标记为脏位时,对应的 Cache 行替换时将数据写回主存(当发生缓存读的冲突不命中时,访问两次内存,第一次写回脏数据,第二次读取所需数据)
写不命中
- 现象: 想要写入数据的地址不在缓存中
- 处理策略
- 写分配/写时取(Write Allocation/Fetch on Write): 未写入数据先载入缓存,然后执行写命中操作
- 无写分配(No Write Allocation): 数据直接写入主存,不干扰缓存,仅在读不命中时载入缓存(适用场景: 写入数据无需立刻使用)
Cache 缓存命中步骤
- 组匹配
- 行匹配(标志位比对)
- 数据块内部偏移匹配获取对应数据
前两个步骤匹配失败,则缓存不命中
相关指标
命中率
- 定义: CPU 访问主存数据时,命中 Cache 的次数占全部访问次数的比率
- 影响因素: 程序行为,Cache 容量,组织方式,块大小
- 命中率: ,其中 为 Cache 完成存取的次数, 为主存完成存取的次数
系统平均访问时间
- 平均访问时间: , 为 Cache 访问时间, 为主存访问时间
访问效率
- 设 表示主存访问时间相比 Cache 访问时间的倍数
- 访问效率: ,其中,以 较佳
地址映射方式
预设:
- 存储器: 地址 位, 大小为
- Cache
- 共 组
- 每组有 行,包括 字节的数据块
- 大小 (不计标记位和有效位)
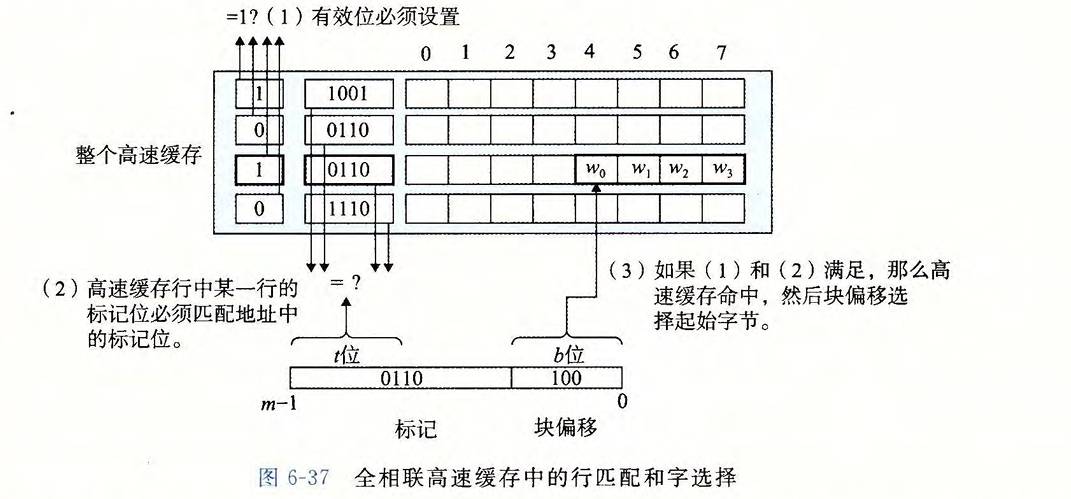
全相联映射
- 流程
- 组匹配: 组索引中定位组(只有1组,忽略匹配)
- 行匹配: 遍历组中的每一行,找到有效的且标记位匹配的行(映射到这个组的数据块可以位于任意行)
- 块偏移匹配
- 特点
- 没有冲突不命中的问题,缓存利用率高
- 规模不能太大,太大的话标记位过长,导致电路规模增长,成本较高,查找速度较慢
- 适用于小的高速缓存,如缓存页表项的 TLB
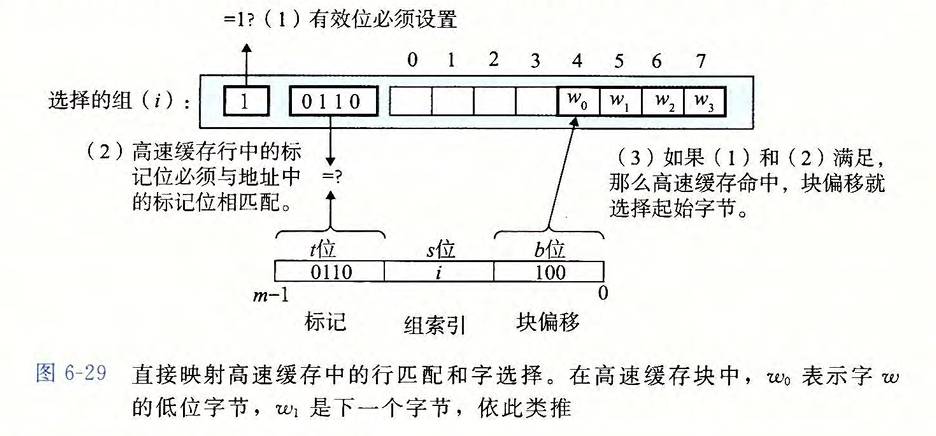
直接映射
- 流程
- 组匹配: 组索引中定位组
- 行匹配: 有效位判断 -> 标记位匹配(只有一行,对应的数据块在哪一行是固定的)
- 块偏移匹配
- 特点
- 映射方式简单,硬件易实现
- Cache 命中率低,替换频繁,可能存在 Cache 有空行但不能存储数据块的问题
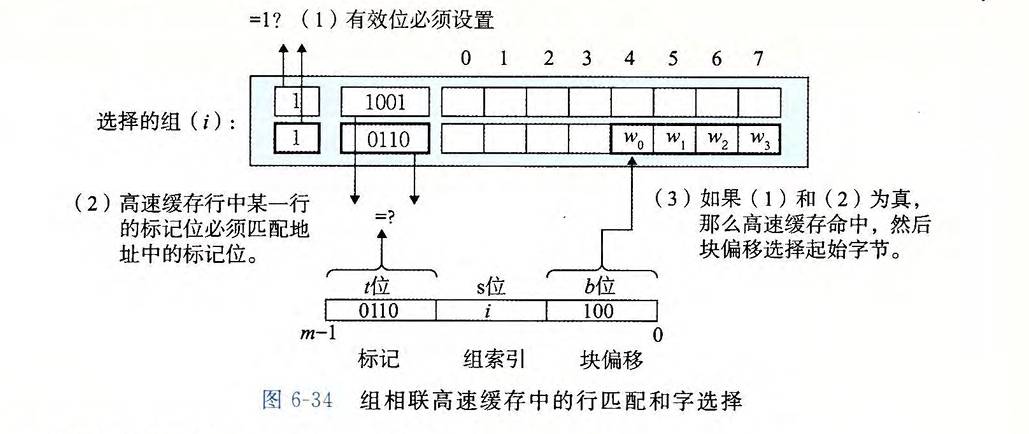
组相联映射
- E 路相联高速缓存
- 全相联映射和直接映射是特殊的组相联映射
- 流程
- 组匹配: 组索引中定位组
- 行匹配: 遍历组中的每一行,找到有效的且标记位匹配的行(映射到这个组的数据块可以位于任意行)
- 块偏移匹配
- 特点
- 通常采用 2路、4路、8路比较
- E较小,硬件开销较小
替换算法
- 随机替换算法
- 先进先出算法(FIFO)
- 最近最少使用算法(LRU Least Recently Used)
- 统计 Cache 行的使用次数(计数器实现)
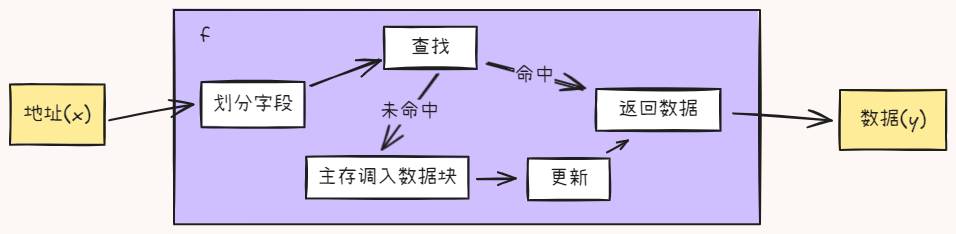
函数模型
其它
这里主要放置一些自己看到的又懒得分类东西
传输关系
- CPU 和 Cache 之间的数据传输以 字 为单位
- 主存 和 Cache 之间的数据传输以 块 为单位
缓存过小时(题外话)
当执行一个程序,该程序所需内存过大,内存基本拉满时,会释放暂时不需要的页,从磁盘载入当前需要的虚拟内存页,但释放的页可能在下一步又要用到,于是又释放暂时不需要的页,从磁盘载入页(现象称为抖动)…这样导致操作系统卡顿(磁盘和主存的数据传输导致)
这部分应该放在虚拟内存篇章比较合适,但 每一层存储设备都是较低一层的缓存,所以放在这里也可以
题外话来源: 虚拟机内存设置 1G,编译代码时磁盘传输速度拉满,界面卡顿
代码中的冲突不命中
来源: 《深入理解计算机系统》
当程序访问大小为2的幂的数组时,直接映射高速缓存通常发生冲突不命中
1 | int func(int x[8], int y[8]) { |
- 预设
- Cache 有 2 个组,直接映射
- 一个块大小 16 字节(容纳4个
int类型的数) - x 起始地址为 0,y 内存地址紧跟 x
- 地址映射如下表
| 元素 | 地址 | 组索引 | 元素 | 地址 | 组索引 |
|---|---|---|---|---|---|
| x[0] | 0 | 0 | y[0] | 32 | 0 |
| x[1] | 4 | 0 | y[1] | 36 | 0 |
| x[2] | 8 | 0 | y[2] | 40 | 0 |
| x[3] | 12 | 0 | y[3] | 44 | 0 |
| x[4] | 16 | 1 | y[4] | 48 | 1 |
| x[5] | 20 | 1 | y[5] | 52 | 1 |
| x[6] | 24 | 1 | y[6] | 56 | 1 |
| x[7] | 28 | 1 | y[7] | 60 | 1 |
-
函数执行过程
- CPU 访问 x[0] 地址,缓存不命中(内部为空),从主存中载入 x[0] ~ x[3] 到缓存组0
- CPU 访问 y[0] 地址,缓存不命中(冲突),从主存中载入 y[0] ~ y[3] 到缓存组0
- CPU 访问 x[1] 地址,缓存不命中(冲突),从主存中载入 x[0] ~ x[3] 到缓存组0
- CPU 访问 y[1] 地址,缓存不命中(冲突),从主存中载入 y[0] ~ y[3] 到缓存组0
…
-
上述过程称为抖动,即高速缓冲反复加载或驱逐相同高速缓存块的组
-
解决方法: 让映射组错位,具体的解决方法是在数组后填充字节。例如
int x[8]->int x[12],这样设置,y 的起始坐标为 48,移到了下一组
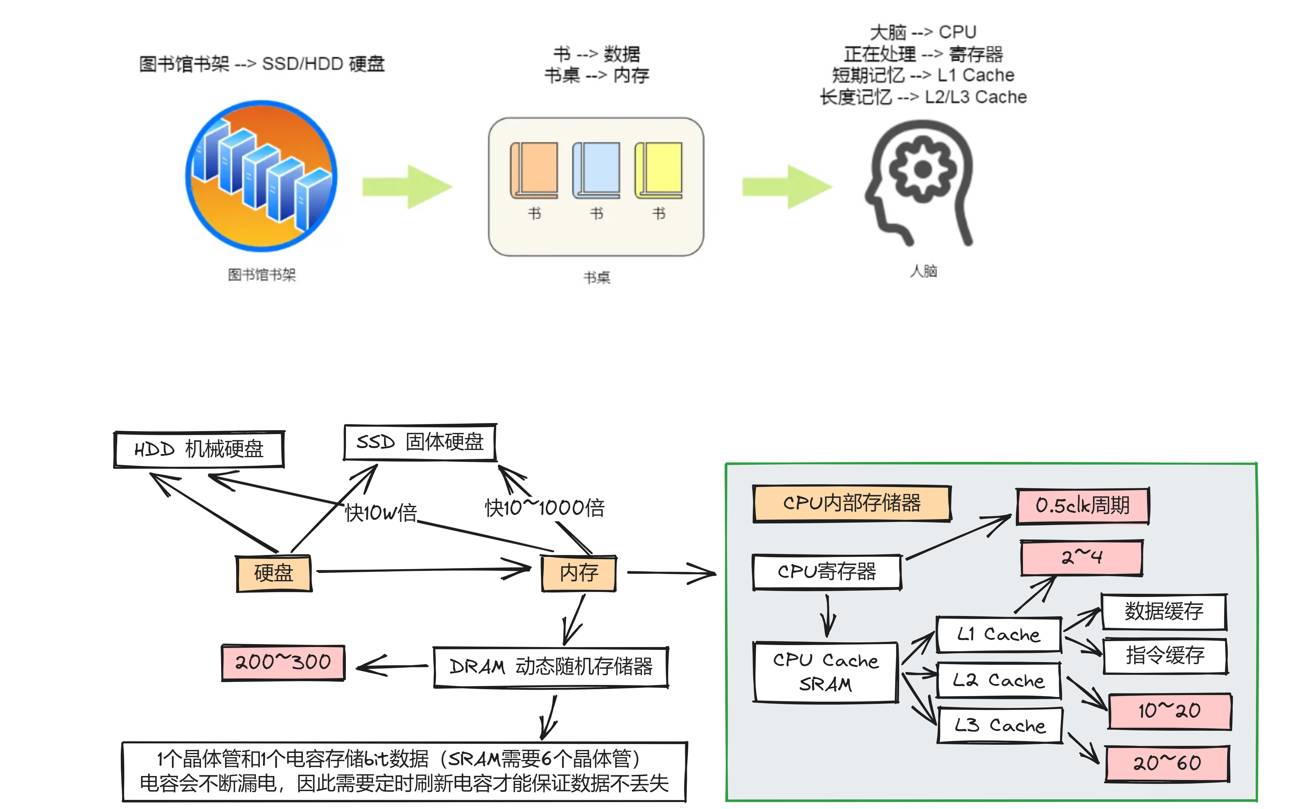
存储相关导图
部分材料来源: 小林coding
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Forgotten Area!